Preprint · 2026
Stability AI
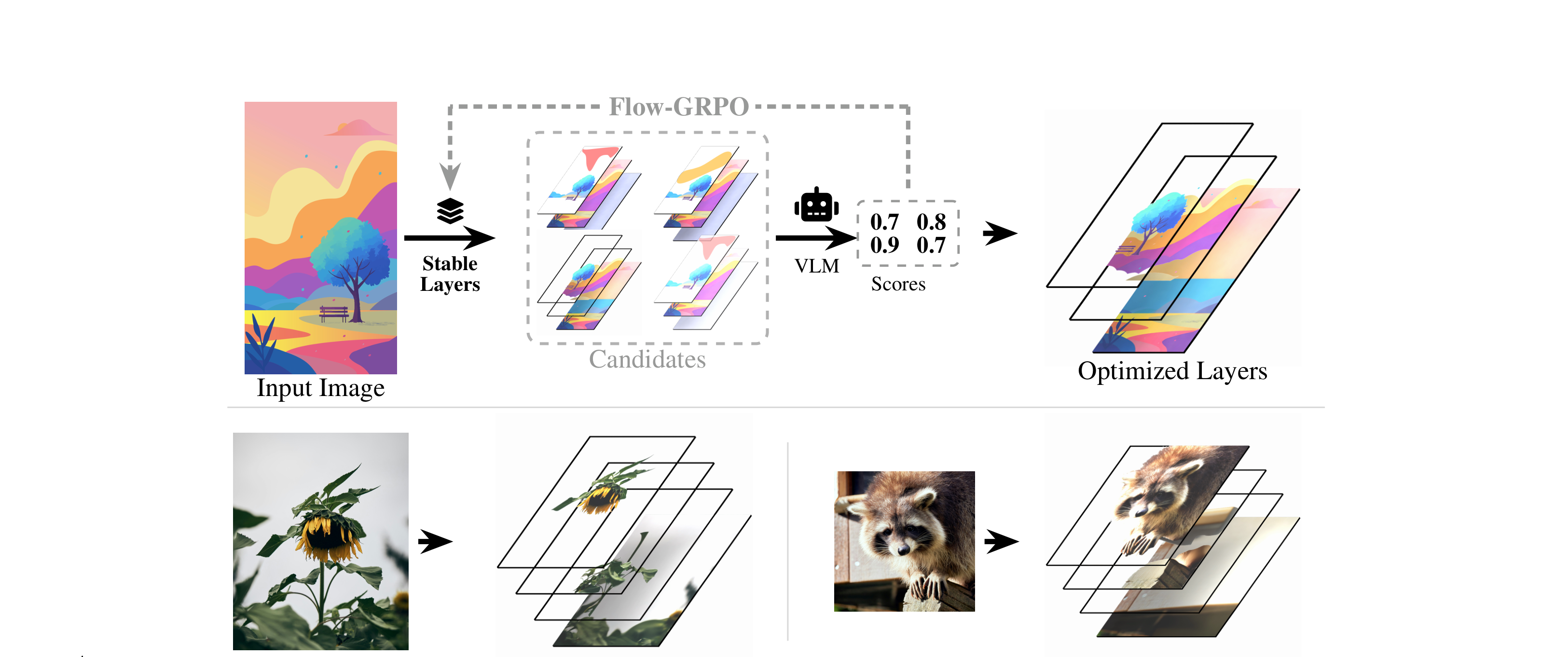
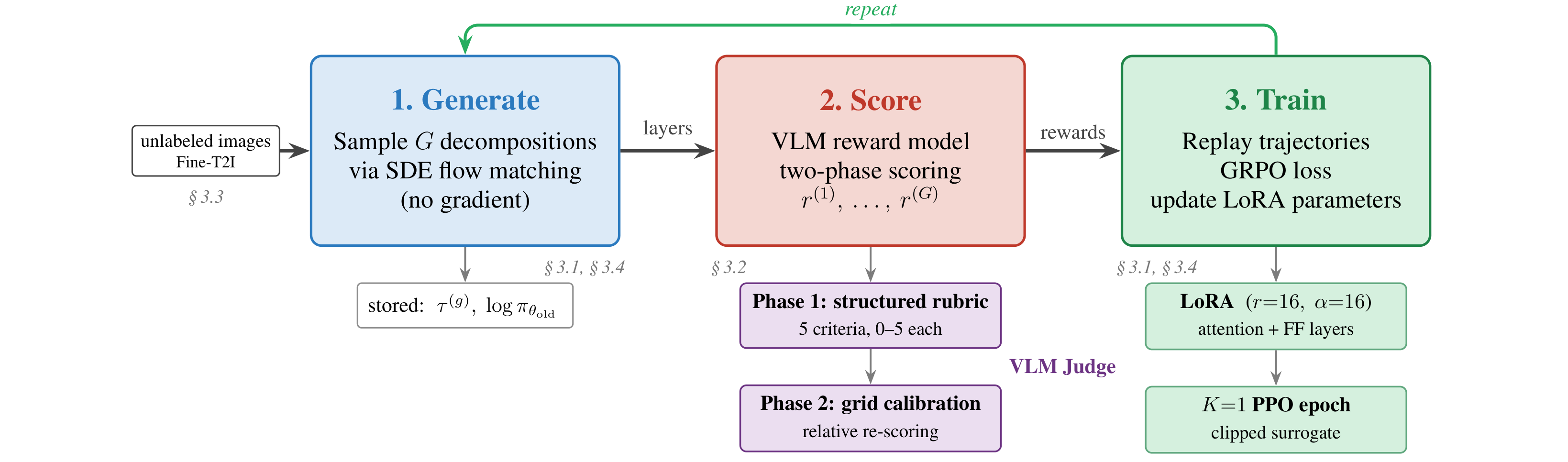
We present Stable-Layers, a reinforcement learning framework that eliminates the need for paired supervision by fine-tuning a pretrained layer decomposition model using only feedback from a vision-language model (VLM). Starting from Qwen-Image-Layered, we apply Flow-GRPO with LoRA adaptation, sampling multiple candidate decompositions per image, scoring them with a VLM, and optimising the policy from group-relative advantages.
The key challenge lies in designing a reliable reward signal: VLMs scoring samples in isolation tend to compress their judgements into a narrow band, leaving GRPO with little within-group variance to learn from. We address this with a two-stage evaluation pipeline that pairs structured per-sample scoring across five edit-centric criteria with a grid-based calibration step in which the VLM re-scores all candidates side-by-side. Trained entirely on unlabelled images, Stable-Layers produces decompositions with stronger layer separation, fewer blank or artifact-heavy layers, and lower per-layer reconstruction error compared to the base model.
Side-by-side decompositions on held-out images. Columns show the input, composite, and individual layers on white backgrounds. The base Qwen-Image-Layered model frequently leaves Layer 0 degenerate and duplicates the composite across foreground slots; Stable-Layers isolates distinct semantic elements with cleaner alpha masks and less colour bleed into transparent regions.

L1 error of each predicted layer against held-out references, grouped by the number of layers L. Lower is better. Stable-Layers reduces mean error across all settings and consistently improves the earlier layers, with the largest gains on the dominant first layer (Pred 0).
@article{rowles2026stablelayers,
title = {Stable-Layers: Fine-Tuning Image Layer Decomposition Models
with VLM-Scored Reinforcement Learning},
author = {Rowles, Ciara and Adithyan, Reshinth and Pinnaparaju, Nikhil
and Voleti, Vikram and Boss, Mark},
journal = {Preprint},
year = {2026}
}